Este set contiene 14 variables químicas de vino hechos en una región de Italia, pero de 3 viñedos diferentes. Es un set bastante limpio sin datos faltantes.
No presenta un problema como tal, sino que provee datos que nos permiten encontrar estructuras y consistencias entre los vinos de cada viñedo, presentando un claro problema de clasificación, donde a partir de cualidades podemos tratar de inferir a que viñedo pertenecería.
Atributos
| Atributo | Tipo | Descripción |
|---|---|---|
| Class | Categórico | Número del Viñedo del que proviene, atributo objetivo. |
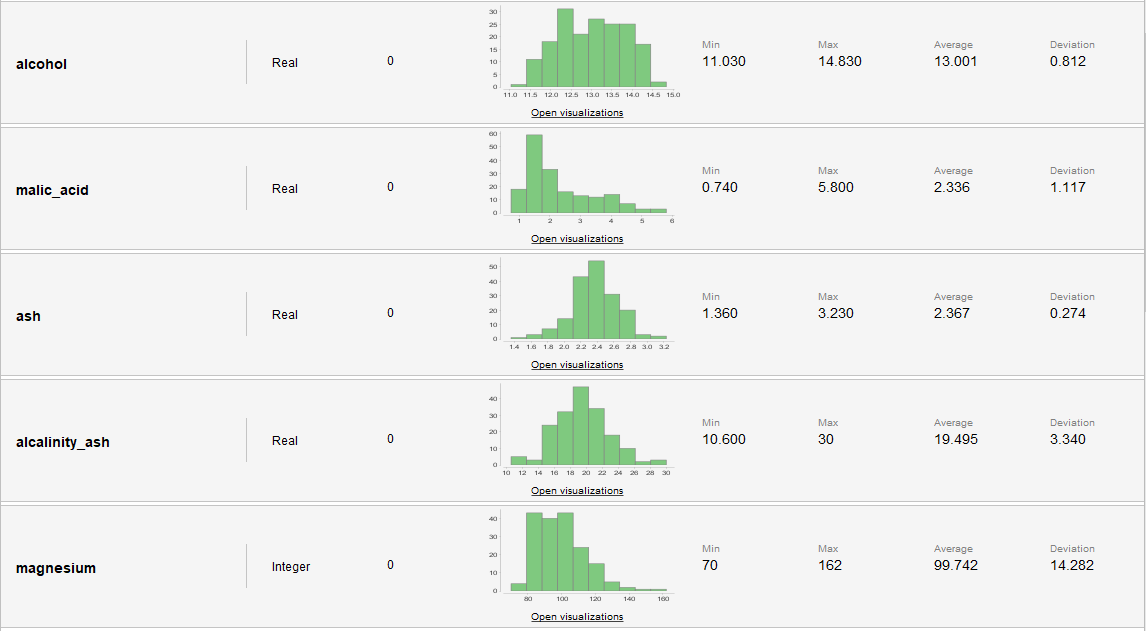
| Alcohol | Real | |
| Malicacid | Real | |
| Ash | Real | |
| Alcalinity_of_ash | Real | |
| Magnesium | Entero | |
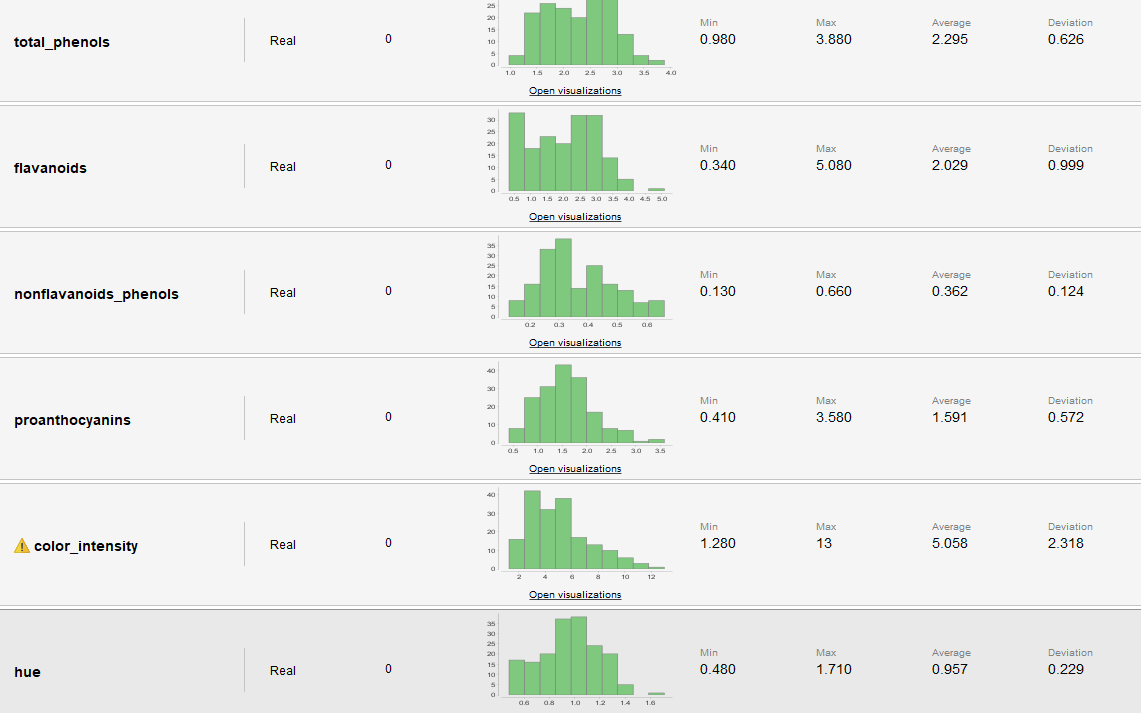
| Total_phenols | Real | |
| Flavanoids | Real | |
| Nonflavanoid_phenols | Real | |
| Proanthocyanins | Real | |
| Color_intensity | Real | |
| Hue | Real | |
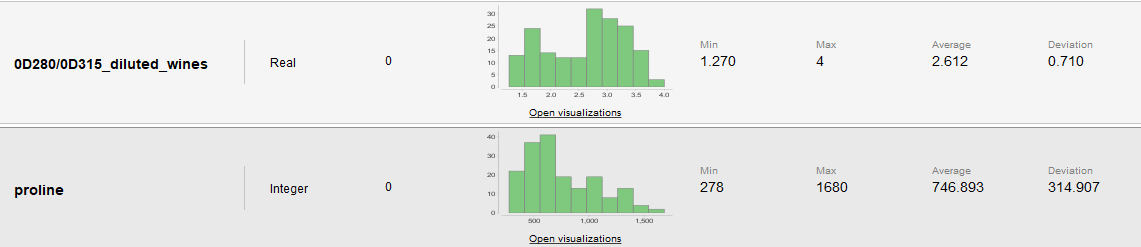
| 0D280_0D315_of_diluted_wines | Real | |
| Proline | Entero |
Estadísticas y Distribuciones
Proceso Utilizado y Resultados
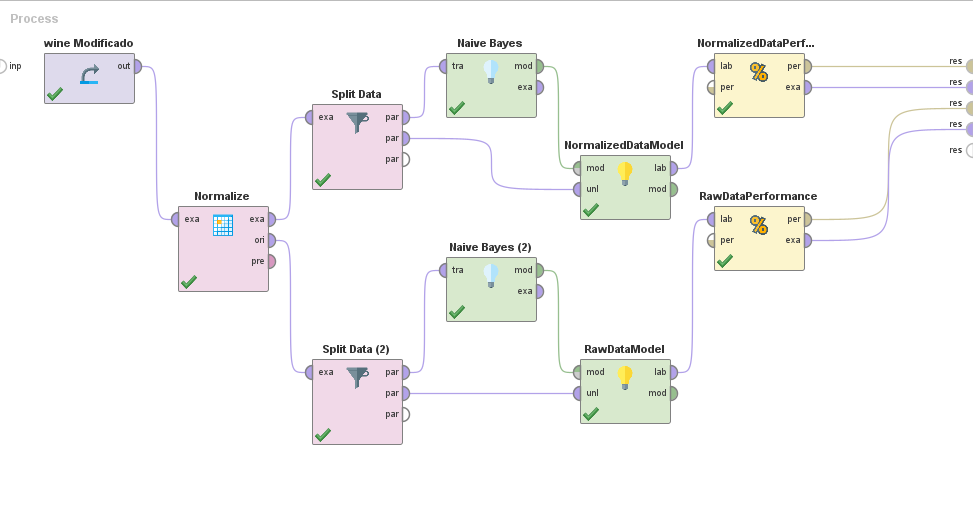
- Las particiones son automáticas y dividen en conjuntos de 70/30 los datos, para entrenar y testear respectivamente.
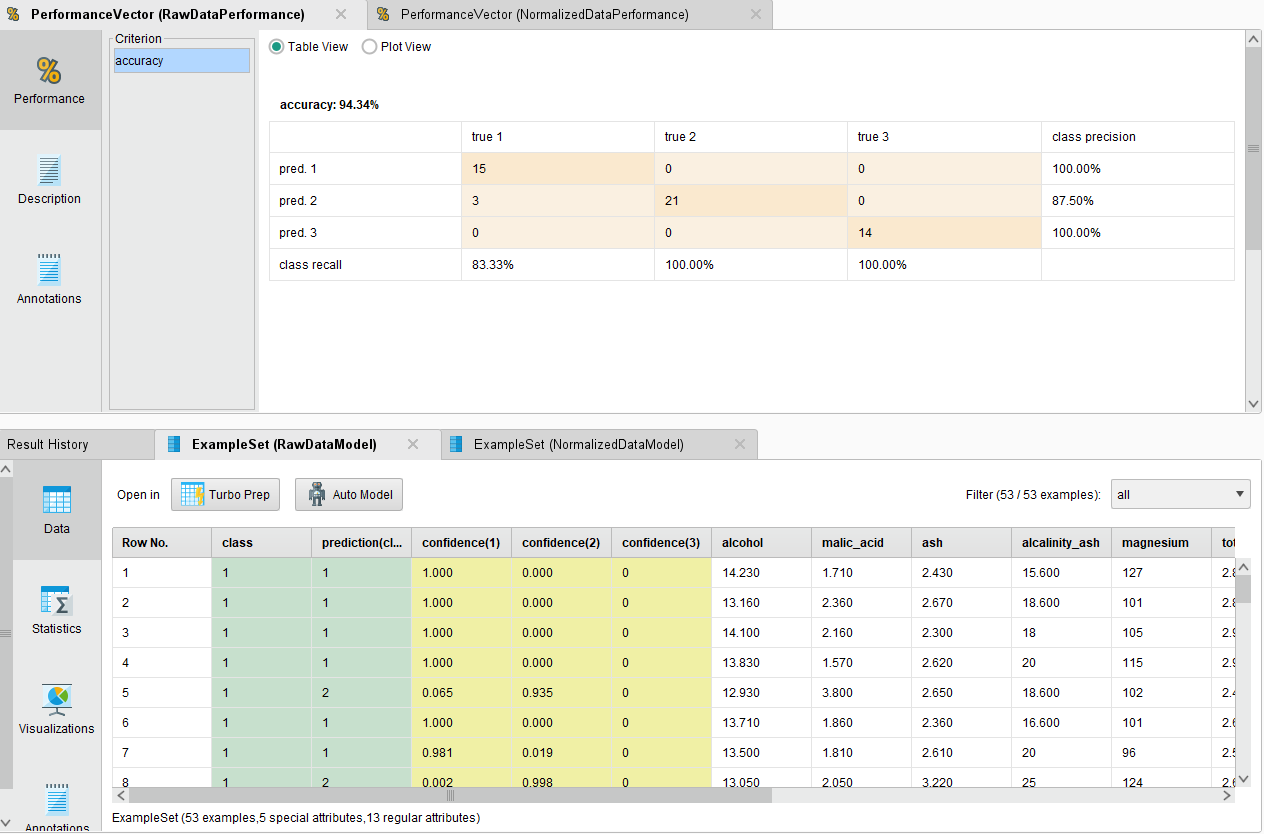
Para datos sin normalizar
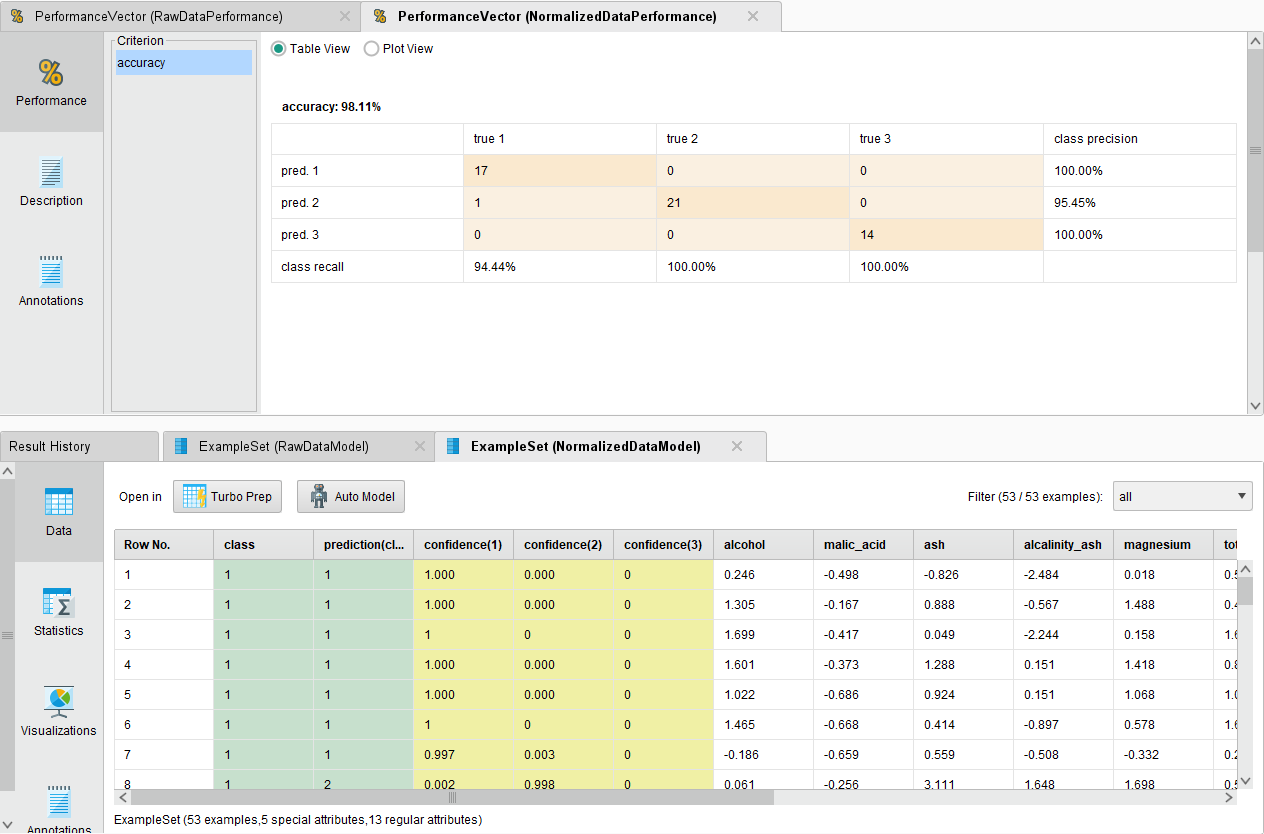
Para datos normalizados
Conclusiones
Se denota una mayor precisión de clasificación en los datos que nos normalizados previamente a entrenar al modelo, una diferencia considerable (aproximadamente 10%).
Esto se puede deber a que el modelo entrenarse con datos distribuidos en rangos similares, logra encontrar estructuras específicas mejor, por lo que es mejor clasificando, mientras que datos con rangos muy diferentes le es más difícil inferir características específicas.