¿Qué es “Machine Learning”?
Hacer una búsqueda rápida y listar al menos 3 definiciones de “Machine Learning” y responder: - ¿qué tiene en común y en qué se diferencia de “Inteligencia Artificial”? - ¿qué tiene en común y en qué se diferencia de “Análisis Estadístico”? - ¿Cómo se diferencia con Data Mining? - ¿en qué se aplica?
The process of computers changing the way they carry out tasks by learning from new data, without a human being needing to give instructions in the form of a program ~Cambridge
Machine learning es una forma de la IA que permite a un sistema aprender de los datos en lugar de aprender mediante la programación explícita. ~IBM
(...) es el subcampo de las ciencias de la computación y una rama de la inteligencia artificial, cuyo objetivo es desarrollar técnicas que permitan que las computadoras aprendan. Se dice que un agente aprende cuando su desempeño mejora con la experiencia y mediante el uso de datos; es decir, cuando la habilidad no estaba presente en su genotipo o rasgos de nacimiento ~Wikipedia
Muchas fuentes acuerdan que Machine Learning e Inteligencia Artificial con conceptos contenidos, Machine Learning refiere a una forma de desarrollo de IA basado en el aprendizaje automático a partir de datos históricos, donde el programador no provee un algoritmo específico de como predecir o tomar una decisión, sino que presenta los datos históricos para que el sistema haga predicciones basadas en estadística. La IA es un concepto más amplio, que abarca varias técnicas de lograr su propósito de simular el pensamiento y razonamiento humano.
Similarmente, el ML y el análisis estadístico no son conceptos completamente ajenos entre si. Los modelos de ML utilizan conceptos matemáticos definidos en el análisis estadístico para sacar provecho de los datos que se le alimentan, utilizándolos para hacer predicciones. El análisis estadístico es más abarcativo no obstante, ya que ademas de enfocarse en el hallazgo de relaciones entre variables, también toma foco en el examen, comprensión e interpretación de los datos. Este tipo de análisis se debe comprender dentro del trabajo que realicemos en ML.
El data mining es similar en el sentido de su enfoque centrado en datos, ya que utiliza estos, los recopila de varias fuentes, procesa y limpia en busca de patrones o información útil o importante. Mientras que el ML se centra en la definición automática de algoritmos predictivos, el data mining se centra en los datos que ya existen, y su interpretación y valor propio. Ejemplos de uso de Data Mining es para la evaluación de clientes, analizar ventas o detectar fraudes financieros, ámbitos donde se cuentan con datos extensivos y se buscan ordenar los datos, hallar patrones y anomalías.
Breve investigación de herramientas y plataformas para Machine Learning.
- Listar los nombres, url donde se la describe y características más importantes:
- Funcionalidades disponibles (bloques / scripts / librerías) para
- Tratamiento de datos
- Algoritmos
- Prueba y validación
- Capacidades de integración con aplicaciones (embebidas, cloud/web-services)
Desarrolla un breve documento de resumen, que podrás adaptar e incluir en el portafolios. Asegúrate de incluir RapidMiner y Weka.
RapidMiner : https://rapidminer.com/ Es una herramienta que facilita la implementación de ML con una interfaz sencilla de usar pero con una gran capacidad a nivel industrial.
Weka : https://www.cs.waikato.ac.nz/ml/weka/ Son una colección de algoritmos de aprendizaje que permiten ML, Data mining, deep learning y más en un entorno tan flexible como es Java, que facilita su conectividad con otros sistemas.
TensorFlow : https://www.tensorflow.org/?hl=es-419 Enfocada en el aprendizaje automático, TensorFlow facilita la definición de modelos y su entrenamiento e implementación en todo tipo de dispositivo.
RapidMiner y Weka cuentan con capacidades y funcionalidades similares, donde ambas permiten amplias integraciones y funcionalidades, separándolas la interfaz gráfica intuitiva de RapidMiner dándole una facilidad de uso superior. Por otro lado, TensorFlow está mas centrado para redes neuronales y deep learning. Este y RapidMiner cuentan con integración a la nube.
Algoritmos de ML
La siguiente figura muestra una clasificación típica de algoritmos y aplicaciones de los mismos.
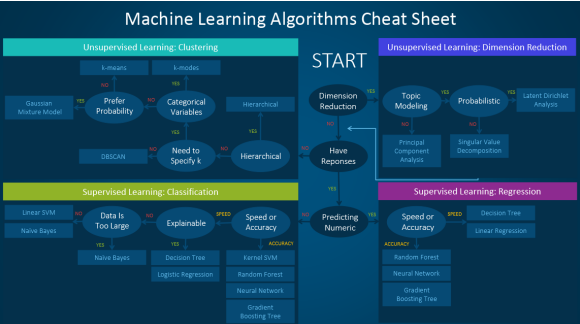
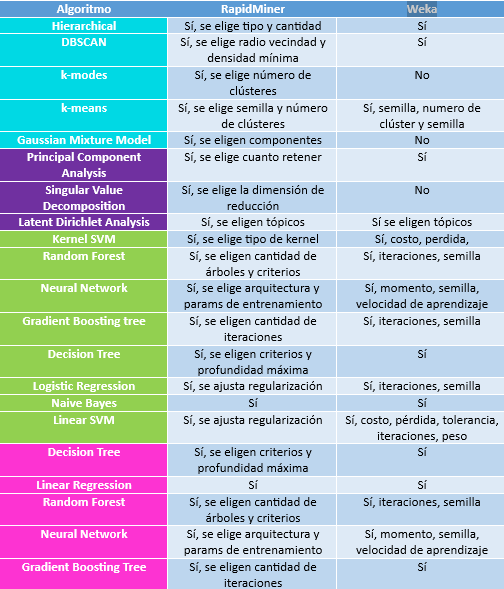
A partir de ésta, analiza algunas de las herramientas / plataformas que identificaste en el Ejercicio 2, observando cuáles algoritmos son soportados, y haciendo una revisión rápida de los parámetros que aceptan. Haz una tabla comparativa para al menos 2 herramientas. Asegúrate de incluir RapidMiner.
Procesos de Data Science
Busca información detallada del proceso CRISP-DM y realiza un breve resumen. ¿Qué otros procesos similares existen? ¿En qué se asemejan a CRISP-DM y en qué se diferencian
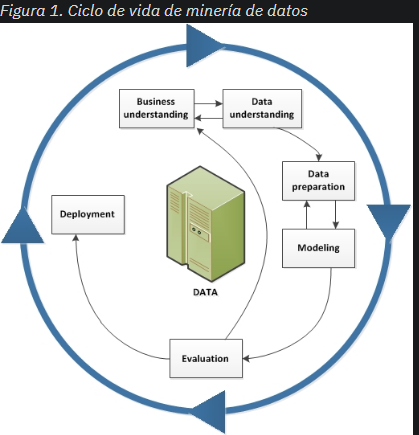
CRISP-DM o Cross-Industry Standard Process for Data Mining es una metodología para orientar trabajos y ciclo de vida de minería de datos.
Cuenta con 6 pasos:
- Entender el negocio
Se exploran y definen expectativas para el trabajo de minería de datos junto a stakeholders. Se define un plan de proyecto.
- Entender los datos
Implica explorar los datos disponibles para evitar problemas en la preparación de datos luego. Evaluar cuales serán útiles o no, si hay suficientes, de que manera están definidos entre varias otras verificaciones.
- Preparar los datos
Muy importante y de los más longevos, consiste en las transformaciones de los datos según lo que busquemos. Pueden ser fusiones, selecciones, derivación de atributos nuevos, limpieza de datos, division de datos de prueba y entrenamiento, entre otros.
- Modelado
Se trata de aplicar modelos en varias iteraciones para comprender el problema planteado en las primeras fases. Algunos modelos pueden requerir volver a preparación de datos.
- Evaluación
En esta fase se evalúan los modelos utilizados para la realización del plan de proyecto, la evaluación de la correctitud de los modelos usados y sacar conclusiones de los resultados obtenidos, con consideración de interferencias.
- Despliegue
Consiste en integrar los descubrimientos con el negocio, utilizar lo que se descubrió para mejorar.
Procesos alternativos a CRISP-DM son KDD y SEMMA.
KDD o Descubrimiento de Conocimiento en Bases de Datos es un proceso para el data mining en una escala macro. Se centra en encontrar patrones en datos para llevar a nuevos conocimientos. Este método cuenta con 9 fases, donde solo 1 de estos es la minería de los datos en sí. En términos amplios, es similar a CRISP.
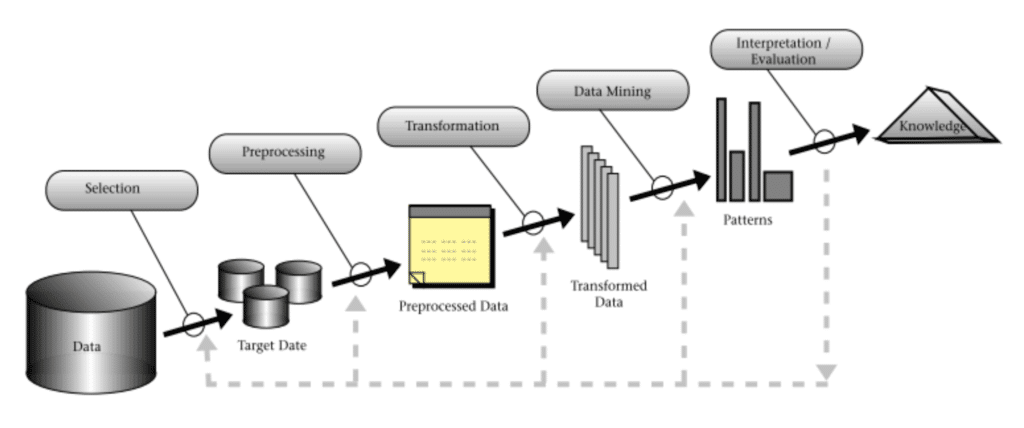
SEMMA es un proceso desarrollado por el Instituto SAS. SEMMA es un acrónimo para las fases que engloba este proceso: Sample, Explore, Modify, Model y Assess. Este modelo es más corto y al pie, mas enfocado en la construcción de un modelo apto y no tanto en el valor al negocio que debe aportar, no porque este no importe sino porque se da como entendido.
Utilizando los datasets del repositorio UCI:
- Selecciona un dataset interesante, complejo, y que preferentemente haya sido objeto de muchas investigaciones
- Identifica el problema que aborda
- Estudia los atributos : tipos de datos, significado, rangos, cómo afectan a la(s) variables de predicción
- ¿qué tipos de algoritmos de Machine Learning pueden aplicarse para resolverlo? (revisa rápidamente algunas publicaciones referenciadas)
Dataset: Heart Disease en http://archive.ics.uci.edu/dataset/45/heart+disease
El propósito de este set es de predecir la presencia de una enfermedad cardíaca en pacientes.
Utiliza datos de edad (numero), sexo (categórico), tipo dolor de pecho (categórico), presión sanguínea (numero), colesterol (numero), azúcar en sangre en ayuno (categórico), resultados electrocardiograma (categórico), valor máximo de frecuencia cardíaca (numero), angina inducido por ejercicio (categórico), depresión cardiaca (numero), pendiente de ejercicio (categórico), numero de vasos sanguineos principales (numero), thal (categórico), diagnostico (Numero, Target).
Según las estadísticas, los modelos con mejor desempeño son de clasificación (Random Forest, Support Vector, Neural Network) y uno de regresión logistica.